[NeurIPS 2023] Characterizing the Impacts of Semi-supervised Learning for Programmatic Weak Supervision
Yejin Kim2024. 2. 10. 22:47
Motivation
Machine learning 분야에서 labeled data가 부족하다는 문제를 해결하기 위해 weak supervision (WS)과 semi-supervised learning (SSL)이 제안되었다.
Programmatic weak supervision: 비교적 cost가 적은 noisy label을 사용하여 학습
Semi-supervised learning: 추가적으로 unlabeled data를 활용하여 학습
두 분야가 가지는 본질적 공통점들이 있기 때문에, 메소드들이 서로 보완적으로 적용될 수 있어 보이지만 아직까지는 두 분야의 intersection이 잘 연구되지 않았다.
따라서 이 연구에서는 WS을 기반으로 SSL을 언제, 어떻게 사용하는 것이 효과적인지에 대해 체계적으로 연구를 수행하고자 하였다.
Design space
○ 문제 정의
Weak supervision (WS)
데이터의 분포 P를 따르는 unlabeled training setD={xi}ni=1∈Xn가 있다. 이에 대한 label은 labeling function (LFs){λj}mj=1를 통해 얻고, 각 λj는 해당 데이터 xi에 대해 label ~yi혹은 ∅ (labeling을 하지 않음) 을 output으로 하는 함수이다. WS에서 label model (LM)은 (D,{λj}mj=1)로부터 weak labeled training set˜D={(xi,~yi)ni=1를 만들어낸다. 그리고 discriminative end model (DM) f는 ˜D를 활용하여 모델을 학습시킨다.
여기서 문제가 되는 것은 (1)˜D가 uncovered example을 종종 포함하고 있다는 것이다. 우리가 가지고 있는 모든 LF가 어떤 example에 대해 ∅를 output으로 가진다면 이 data는 일반적으로 학습에 사용되지 않는다. 또한 (2) ˜D가 잘못된 label을 포함한다는 문제도 있다. 이 논문에서는 이러한 WS의 문제 상황에서 SSL이 ˜D를 더 효과적으로 학습할 수 있도록 하는지를 살펴보고자 한다.
Semi-supervised learning (SSL) SSL은 labeled datasetL={(xli,yi)}|L|i=1과 unlabeled datasetU={(xui)}|U|i=1가 있다고 가정한다. 한정된 크기의 L를 가지고도 모델이 좋은 성능을 가질 수 있도록 하는 것이 SSL의 목표이다.
○Design Space
기본적인 WS의 파이프라인을 고려하여 저자들은 세 가지 디자인 요소를 다음과 정의하였다.
Thresholding labeled data와 unlabeled data를 어떻게 나눌 것인가?에 대한 디자인 초이스이다. WS setting에서 너무 noisy한 label은 unlabeled data로 간주하는 것이 나을 수도 있다. 기본적으로 WS에서는 covered/uncovered example을 기반으로 L을 결정한다. 이 논문에서는 다음과 같은 partitioning을 고려하였다.
- Coverage-based (default): uncovered point를 제외한 데이터를 활용 - Confidence-based: 낮은 confidence 값을 가지는 example들을 제외한 데이터를 활용 - Cut-based: label이 nearest neighbor label들의 분포와 다르게 예측되는 example을 제외한 데이터를 활용
SSL Technique unlabeled data로 분류된 데이터를 어떻게 사용할 것인가?에 대한 디자인 초이스이다. 기본적으로 WS에서는 unlabeled image를 사용하지 않는다. 이 논문에서는 다음의 방식으로 SSL을 적용하였다.
- Entropy minimization (EM): unlabeled example들의 uncertain prediction을 penalize하도록 학습 - Self-training (ST): 현재의 prediction을 true label처럼 사용하여 학습하는 형태. 이 논문에서는 ST 방식을 end model을 추가적은 LF λm+1로 활용하는 것으로 구체화하였다. - Consistency regularization: unlabeled data에 변화를 주어도 비슷한 output을 가지도록 학습하는 형태. 여기서는 VAT를 사용
Re-labeling SSL의 기본 문제 setting에서 L의 모든 label은 정답임을 가정한다. 하지만 WS에서는 그렇지 않을 수 있기 때문에 L의 label 또한 end model을 통해 다시 labeling 하는 것을 하나의 디자인 초이스로 고려해 볼 수 있다. 이 논문에서는 다음의 두 가지 방식의 re-labeling 기법을 살펴본다.
- end model의 prediction을 바로 사용 - end model을 추가적인 LF로 하여 LM을 리모델링 하는 것이다.
여기서 두 번째 방식은 SSL의 ST와 동일하다. 따라서 ST를 제외한 나머지 SSL 기법에 대해서는 두 번째 방식의 re-labeling을 사용하지 않도록 하여 어떤 SSL technique이 효과적인지를 확인하기 용이토록 실험을 구성한다.
○기존 기술 체계화
기존 기술들을 위에서 정의한 design space를 토대로 체계화하면 다음과 같다.
위의 표는 WS에 대한 체계적인 연구가 부족했음을 보여주고 있다. 여러가지 기술들이 각각 다르게 통합되어 메소드가 만들어짐에 따라 어떤 요소가 WS에 효과적인지 분석하기가 힘들다.
Experiments
○실험 세팅
데이터셋과 모델 Table 2에 있는 총 8개의 classification dataset을 사용했다. End model은 거의 WRENCH 의 configuration을 따른다. NLP task에 대해서는 RoBERTa pre-trained model을 fine-tune한 것과 fronzen ROBERTa embedding에 MLP classification head 추가하여 학습시킨 모델을 모두 사용하였다. (후자에 대한 실험 결과는 appendix에 있다고 함) tabular task에 대해서는 단순히 MLP를 학습시켜 사용했다. LM은 어떤 것을 사용해도 상관없지만 여기서는 Snorkel LM으로 만든 soft-label을 활용하였다.
Design space 내에서 충분히 경쟁력 있는 메소드를 만들 수 있는가?
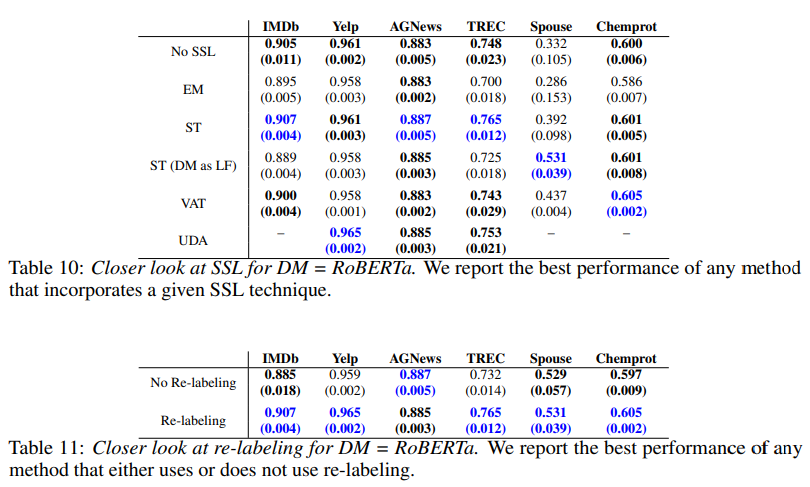
End model이 RoBERTa일 때 best single method는 dynamic confidence thresholding, ST, re-labeling의 조합인 메소드이다. 이 메소드는 task 7개 중 5개에서 다른 baseline들에 견줄만한 성능을 보였다. 또한 이 design space 내에서 dataset 별로 모든 조합의 성능을 확인하였을 때 기존의 메소드들을 outperform하는 메소드를 찾을 수 있었다. 이를 통해 앞서 정의한 design space 내에서만 분석을 진행하는 것이 어느정도 정당하다는 것을 실험적으로 보였다.
현재 벤치마크에서 가장 중요한 축은 무엇인가? 위의 Table 3의 Method는 해당 method 카테고리 내에서 가능한 방식의 모든 조합을 실험했을 때 best 성능을 report 한 것이다 (예를 들어 "Thresh + SSL"인 경우 {Conf-based, Cut-based} x {EM, VAT, UDA, ST, ST w/ DM} 의 모든 조합을 실험하여 최고의 성능을 보고한 것). 표를 보면 Spouse 데이터셋을 제외하고 나머지 6개의 task에서는 "Thresh + Re-label"만으로도 "Vanilla"와 "Thresh + SSL + Re-label" 성능 gap의 약 90%를 채울 수 있다. 저자들은 이러한 실험 결과에 대해서 SSL이 현재 벤치마크에 필수적이지는 않으며, SSL이 제한된 시나리오 하에서 효과적이라고 주장한다. 특히 (1) LF가 Spouse 데이터셋을 잘 cover하고 있지 않기 때문에 SSL이 효과적이었음을 주장하였고, (2) MLP를 사용하였을 때에는 "Thresh + Re-label"이 68% 정도만을 채웠는데 이를 통해 model의 size도 SSL의 효과성에 영향이 있을 수 있을 것이라 추측한다. MLP에 대한 실험 결과는 다음의 Table 9를 통해 확인할 수 있다.
각 축마다 좋은 성능을 보이는 기술은 무엇인가? 이번에는 각각의 요소에 대해 살펴본다.
- Thresholding
Thresholding은 대부분의 경우 효과적이었다. 간단한 confidence-based threshold도 Chemprot 데이터셋을 제외하고는 cut-based 방식에 견줄만한 성능을 보였다.
- SSL and Re-labeling
SSL과 Re-labeling은 비슷한 경향을 보였다. 한, 두 개 정도의 데이터셋을 제외하고는 SSL과 Re-labeling이 성능을 크게 향상시키지 않았다. 하지만 MLP 모델에 대해서는 SSL이 비교적 효과적임을 다음의 그림에서 확인할 수 있다. (No SSL이
SSL 기술은 언제 필요한가? 저자들은 WS에서의 데이터 문제를 다음과 같이 정리하였다. (1) 제한된 크기의 labeled data (2) Coverage bias: LF에 따라 labeled data에 편향성이 생길 수 있음 (3) Label noise: 잘못된 class로 label이 만들어질 수 있음 그리고 SSL이 문제 (1), (2)가 심한 상황에서 효과적인 역할을 할 수 있다고 주장한다.
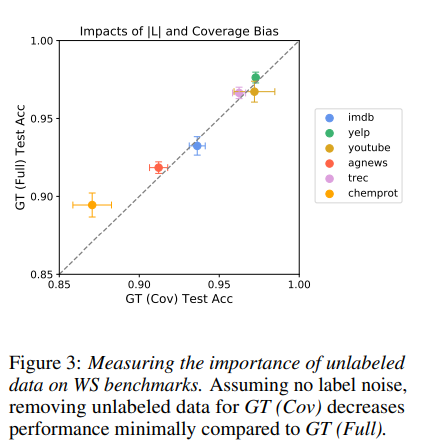
Figure 3에서 GT (Cov)는 LF-coveraged input에 대해 만들어진 label로 학습된 모델, GT (Full)은 전체 D의 labeled version에서 학습된 모델을 의미한다. 기존의 WRENCH 벤치마크에서 GT (Cov)와 GT (Full)은 비슷한 거의 비슷한 성능을 보인다. 이는 현재 존재하는 벤치마크들의 가장 주요한 데이터 문제는 label noise라는 것이다.
LF-coveraged input이 낮은 경우에 대한 실험을 진행하기 위해 Massive18, Banking77, Mushroom, Spambase, PhishingWebsites 데이터셋을 활용하였다.
Figure 4에서 위의 두 행에 해당하는 데이터셋에 대한 실험 결과를 보면 coverage가 줄어듦에 따라 GT (Cov)의 성능이 확연히 떨어진다. 반면, IMDb, Yelp, AGNews에서는 coverage 10~20%까지로 떨어지더라도 GT (Cov)와 GT (Full)의 성능 차이가 2% 내외이다. 이렇게 GT (Cov)의 성능을 기반으로 데이터셋을 나눈 것은 SSL의 효과성을 기반으로 데이터셋을 나눈 것과 일치한다. 위의 두 행의 데이터셋에서는 lower coverage level에서 "Thresh + SSL"이 "Thresh + Re-label"을 항상 outperform 한다. 반면, 아래 행의 데이터셋에서는 "Thresh + SSL"이 "Thresh + Re-label"의 오차범위 내의 성능에 그쳤다.
정리하면, 이러한 실험 결과들은 SSL이 WS setting에서 효과적인지 여부는 벤치마크에 따라 달라진다는 것을 보여준다. SSL은 lower coverage level에서 가치가 있기 때문에 SSL을 사용함으로써 필요로 되는 LF의 수를 줄일 수도 있을 것이라 주장한다.
Conclusion
저자들은 SSL과 WS를 통합하기 위한 design space를 제안하였다.
기존의 WS 벤치마크에서는 unlabeled data를 활용하는 것이 효과적이지 않음을 보였다.
SSL은 LF가 데이터셋을 잘 cover하지 못하거나 MLP를 사용할 때 비교적 효과적이었다.
연구의 한계점
새로운 task에 대해 제안한 design space를 효과적으로 활용할 수 있는 방식에 대한 디테일이 부족함
데이터 문제를 측정하기 위해 GT label을 사용함
Low coverage LF set을 만들기 위해 자동화 방식을 사용함 (실제 사용자가 사용하는 것을 대표하지 못함)
WS 에 대한 논문은 처음 읽어보는 것이라 읽는데 어려움이 있었지만 논문에서 WS의 파이프라인을 구체적으로 설명하고 있어 대략적인 흐름을 빠르게 이해할 수 있었다.
WS 세팅에서 데이터셋의 label은 semantic segmentation일 때 image level의 label과 같이 task에 비해 약한 label을 사용 하는 것 정도로만 생각을 했었는데, weak supervision의 범주가 넓어서 그런지 다양한 종류의 task가 존재하는 것 같았다. 특히 이 논문에서는 vision 보다는 nlp task를 더 메인으로 하는 WS를 다루고 있었다. 그리고 label도 label model을 통해 만들어내는 방식을 사용한다는 점에서 새로웠던 것 같다.
이 논문에서 주장하고 있는 바는 WS 세팅에서 데이터셋이 LF에 의해 lower coverage일 때 SSL이 효과적이라는 것인데 SSL 관점에서는 어쩌면 당연한 이야기 일 수도 있다는 생각이 들었다. Higher coverage 일 때는 대부분의 data가 labeled data가 되고, unlabeled data가 오히려 부족하기 때문에 SSL 세팅에서 unlabeled data를 풍부히 사용할 수 있다는 assumption이 깨지게 된다. 따라서 기존의 SSL의 메소드가 효과적인 역할을 하지 못했을 것이라는 것이 내 생각이다.
그래도 WS 세팅에서 모두가 여러가지 기술들을 적용하며 성능을 높이는데 집중할 때, 어떤 요소가 어떤 역할을 하고 있는 것인지 이를 분석하였다는 점에서 의미가 있으며 앞으로의 WS 분야가 나아가야 하는 올바른 방향을 제시했다고 생각한다.