이 논문은 CVPR 2024에 출판되었으며, 저자는 Hyuck Lee, Heeyoung Kim으로 구성되어 있다.
Motivation
Pseudo-label 기반의 semi-supervised learning (SSL) 알고리즘을 class-imbalance 세팅에서 사용하는 경우 다음의 두 가지 문제가 발생한다.
1. Classifier가 majority class에 편향되는 경향이 있다.
2. 편향된 classifier로부터 생성된 pseudo-label들이 training에 사용된다.
이 문제를 해결하기 위해서는 classifier를 적절히 re-balance하는 것이 필요하다. 하지만 unlabeled set의 class distribution은 (2) 알 수 없는 경우가 많으며 (2) labeled data의 distribution과 일치하지 않을 수 있기 때문에 SSL에서는 classifier를 적절히 re-balance하는 것이 쉽지 않다.
ReMixMatch와 CoMatch는 re-balance 기법을 활용하는 SSL 알고리즘 중 일부이다. 이 메소드들은 unlabeled set이 labeled set과 동일한 distribution을 갖는다는 assumption을 활용하여 re-balance를 진행한다. 따라서 이들은 labeled와 unlabeled set 사이의 잠재적인 distribution mismatch를 고려할 수 없다는 문제가 있다는 것이다.
이 문제를 해결하기 위해 저자들은 Class-distribution-mismatch-aware debiasing (CDMAD) 를 제안한다. 이 방법은 각 class에 대한 classifier의 편향 정도를 고려하여 biased pseudo-label과 test sample에 대한 class prediction을 정제한다. 어떻게 정제하는가에 대해서는 메소드 섹션에서 자세히 설명하도록 하겠다.
Method
일반적으로 훈련된 classifier는 학습한 feature를 기반으로 새로운 sample들에 대해 class prediction을 진행한다. 따라서 학습한 feature와 무관한 이미지에 대해서는 classifier가 모든 class에 대해 uniform하게 probability를 만들 것이라고 예상할 수 있다. 하지만 class-imbalanced set에 대해 학습을 한 경우에는 classifier가 majority에 편향되므로 다른 경향성을 보일 수 있을 것이다.

실제로 Figure 1을 통해 이에 대한 실험 결과를 확인할 있다. Figure 1은 white image (image without any patterns) 에 대해 예측한 class probability 를 보여주고 있다.
그림을 보면 Labeled data의 imbalance ratio
저자들은 이 실험을 통해 solid color image가 training set과 무관하다고 가정하는 것이 어느정도 합리적이라고 볼 수 있다고 하며 (balanced set일 때 uniform한 prediction을 하므로), 따라서 solid color image에 대한 class probability는 온전히 각 class들에 대한 classifier의 biased degree로 생각할 수 있다고 주장한다.
Figure 2는 CDMAD의 전반적인 구조를 보여주고 있다. 그림에서 왼쪽 상단에 있는 Image Without Any Patterns가 바로 classifier의 편향 정도를 계산하기 위해 사용되는 input으로, 논문에서는 white image를 활용하였다. 이렇게 계산한 Classifier의 biased degree를 활용하여 biased pseudo-label와 inference time에서의 prediction을 정제한다.
1. Refinement of pseudo-labels during training
2. Refinement of biased class predictions during testing
Training phase에서 biased pseudo-label을 잘 정제하여 unlabeled data를 학습한다고 하더라도, 전체 training set 자체가 imbalance 하기 때문에 여전히 test sample에 대한 prediction이 편향될 수 있다. 따라서 testing phase에서도 동일하게 biased degree를 뺀 정제된 prediction을 사용한다.
CDMAD as a CISSL extension of post-hoc logit-adjustment (LA)
CDMAD는 labeled dataset과 unlabeled dataset의 class distribution mismatch를 고려한 일종의 logit adjustment (LA) 기법의 확장된 버전이라고 볼 수 있다. LA는 기본적으로 CIL에서 biased classifier를 re-balance 하기 위해 소개된 기법이다. LA는 test sample에 대한 logit에서 class prior
이러한 adjustment는 balanced error rate (BER)에 대해 Fisher consistent 하다는 것이 이미 증명되어 있다.
Fisher consistency는 estimator나 loss function의 설계 및 평가에 관한 개념으로, 특정 조건 하에서 추정 방법이나 학습 알고리즘이 전체 모집단에 적용될 때 정확한 모델이나 파라미터 값을 생성할 것이 보장되는 성질을 말한다.
Estimator나 model이 특정 문제에 대해 fisher consistent하다는 것은 데이터 양이 무한히 많아질 때(샘플의 크기가 전체 모집단 크기에 접근할 때), 해당 방법이 데이터를 생성한 true model이나 파라미터를 복구할 수 있다는 것을 의미한다. 이러한 개념은 확률론의 대수의 법칙과 밀접한 관련이 있으며, 샘플 크기가 증가함에 따라 샘플의 평균이 전체 모집단의 평균에 가까워진다는 아이디어에 기반한다고 한다.
Loss function이 fisher consistent하다는 것은, 이 loss를 true data distribution에 대해 최소화함으로써 얻는 model이 true model과 일치하거나 true distribution에 따라 평균적으로 정확한 예측을 한다는 것이다.
하지만 CISSL 세팅에서는 unlabeled data의 분포를 알 수 없으므로 class prior
CDMAD는 LA의 loss와 굉장히 비슷한 형태를 보이며, LA와 마찬가지로 balanced error에 대해 fisher consistent 하다.
Universal approximation theorem에 의해서
따라서 input
만약 network가 entire population에서 학습되었다면 역시나 universal approximation theorem에 의해서
최종 수식은 BER를 minimize 하는 수식이 되고 따라서 CDMAD의 loss는 fisher consistent 하다.
CDMAD는 LA처럼 fisher consistent한 특성을 가지면서도, class prior 대신
Experiments
이 논문에서는 기본적으로 FixMatch와 ReMixMatch를 baseline으로 하였으며, CDMAD 메소드를 적용하는 경우 다음과 같은 수정 사항이 있었다고 이야기 한다.
1) Hard pseudo-label이나 pseudo-label sharpening을 사용하지 않았음
: Entropy minimization이 종종 특정 class에 대해 classifier가 편향되는 문제를 일으킬 수 있기 때문
2) FixMatch의 confidence threshold를 사용하지 않았음
: 이를 통해 모든 unlabeled sample을 학습에 활용할 수 있도록 함. 기존의 FixMatch와 달리 CDMAD는 pseudo-label을 적절히 refine하기 때문에 모든 pseudo-label을 training에 활용가능하다는 이점이 있다고 함.
3) Unlabeled set의 class distribution이 unknown인 세팅에서는 ReMixMatch에서 사용하는 distribution alignment는 활용하지 않았음
실험은 CIFAR-10-LT, CIFAR-100-LT, STL-10-LT, Small-ImageNet-127에 대해 진행했으며 Evaluation metric으로는 balanced accuracy (bACC), geometric mean (GM)을 사용하였다.
Table 1은 CIFAR-10-LT에 대한 실험이며, 여기서는 unlabeled data의 distribtuion이 labeled data와 동일하다고 가정하였다. 표를 보면 vanilla algorithm은 매우 낮은 성능을 보이고 있으며, class imbalance learning (CIL) 분야의 알고리즘들을 적용하면 어느정도 class imbalance 문제가 완화되지만 그 정도가 미미한 수준에 그친다. 반면 일반적인 SSL 메소드인 FixMatch와 ReMixMatch를 사용하면 성능이 확연히 증가하고, 이를 통해 unlabeled data를 학습에 사용하는 것이 얼마나 중요한지를 확인할 수 있다. 더불어 FixMatch와 ReMixMatch에 class imbalance semi-supervised leanring (CISSL) 기법들을 사용하면 성능이 더욱 오르며, 그 중에서도 CDMAD는 SOTA 성능을 달성하였다.
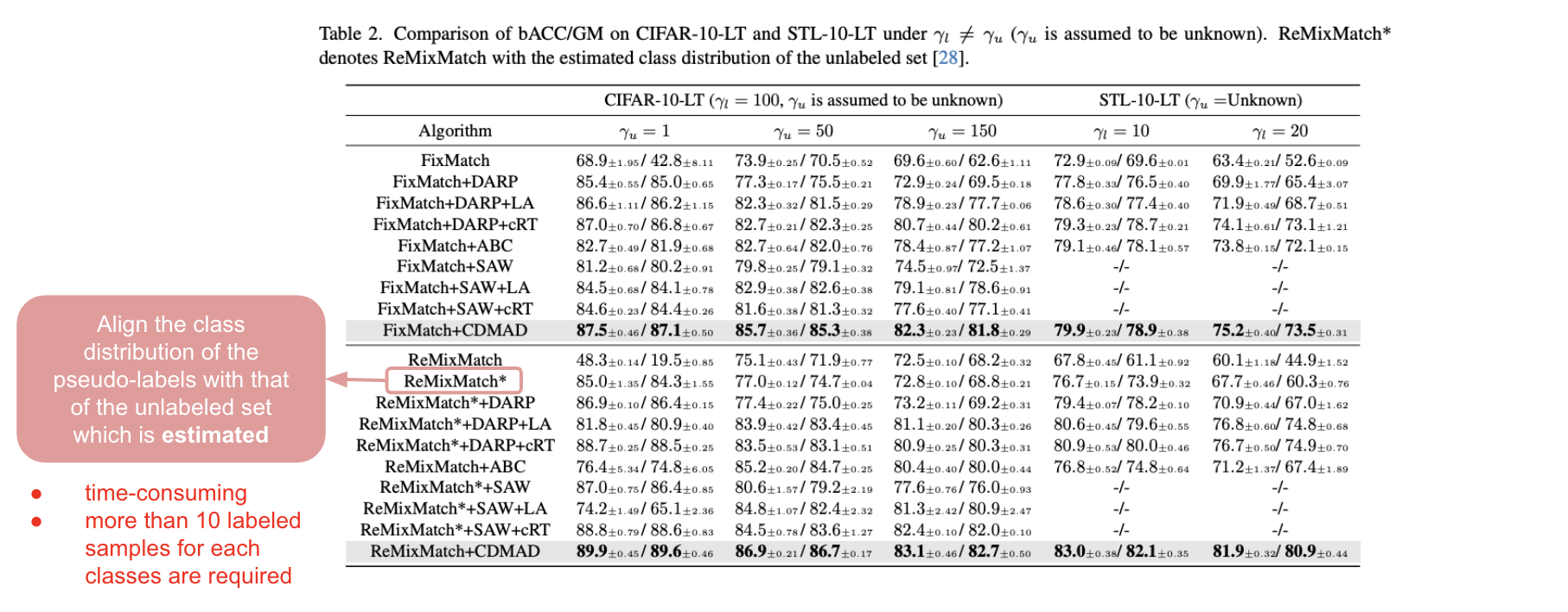
다음 Table 2는 unlabeled data의 distribution이 알져지지 않았을 때에 대한 실험 결과이다. ReMixMatch의 성능이 눈에 띄게 떨어진 것을 확인할 수 있는데, 이는 ReMixMatch가 distribution에 대한 잘못된 assumption을 활용하였기 때문이다. ReMixMatch*는 ReMixMatch의 variation으로 distribution assumption 대신, pseudo-label을 counting한 결과를 토대로 예측한 class distribution을 활용하여 distribution alignment를 진행한 알고리즘이다. 이 알고리즘은 classification 성능을 매우 크게 향상 시킨다. 하지만, unlabeled data의 양이 증가함에 따라 class distribution을 예측하는 것에 시간이 많이 소모되며, estimation 프로세스가 각 class 별로 10장 이상의 labeled set을 필요로 하기 때문에 CIFAR-100-LT와 같이 minority class가 매우 적은 수의 sample을 갖는 경우에는 활용하기가 어렵다.
반면, CDMAD는 unlabeled data에 대한 class distribution 추측 결과에 의존하지 않기 때문에, real-world 시나리오에서 다른 알고리즘들보다 효과적이다.
또한
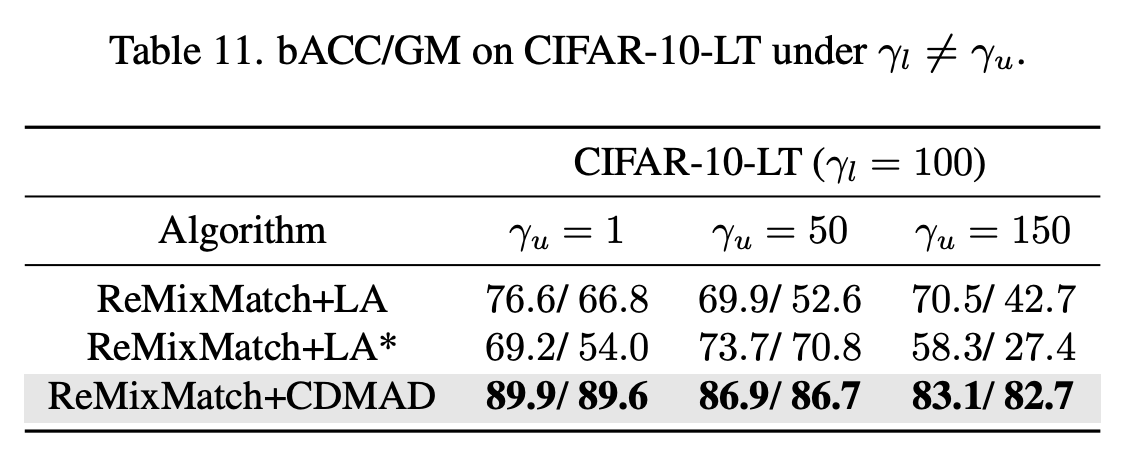
Table 11은 LA와 CDMAD의 성능을 비교한 실험의 결과이다. ReMixMatch+LA는 unlabeled data의 distribution이 labeled data의 distribution과 동일하다는 가정하에 logit을 조정한 것이며, ReMixMatch+LA*는 unlabeled data의 distribution이 알려져 있다는 가정 하에 전체 training set의 class distribution을 고려하여 logit을 조정한 알고리즘이다.
두 가지 방식에 대해 모두 CDMAD가 더 좋은 성능을 보이고 있다. 놀랍게도 LA*는 unlabeled set의 class distribution까지 활용하여 LA를 진행했지만 classifier를 적절한 정도로 re-balance하지 못했다. 저자들은 주로 SSL에서 labeled data들이 unlabeled data 보다 더 자주, 그리고 중요하게 사용되며 따라서 classifier가 labeled set의 class distribution에 더 편향되었을 것이라고 이야기 한다. Unlabeled data에 의해서도 어느정도 편향성이 영향을 받지만, labeled data의 distribution에 의해 더 영향을 많이 받기 때문에 단순히 unlabeled data의 실제 distribution까지 모두 고려하는 것이 높은 성능을 보여주지는 않는다는 것이다.
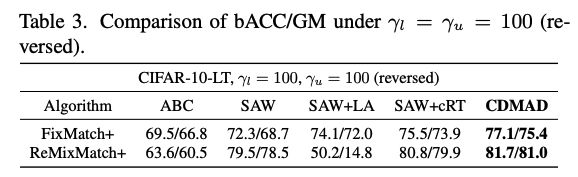
Table 3는 labeled data와 unlabeled data가 동일한 imbalance ratio를 갖지만 그 분포가 역방향인 경우에 대한 실험이다. 즉, labeled data에서의 majority class가 unlabeled data에서는 minority class가 된다. 이 경우에도 CDMAD는 기존의 메소드들을 outperform한다.
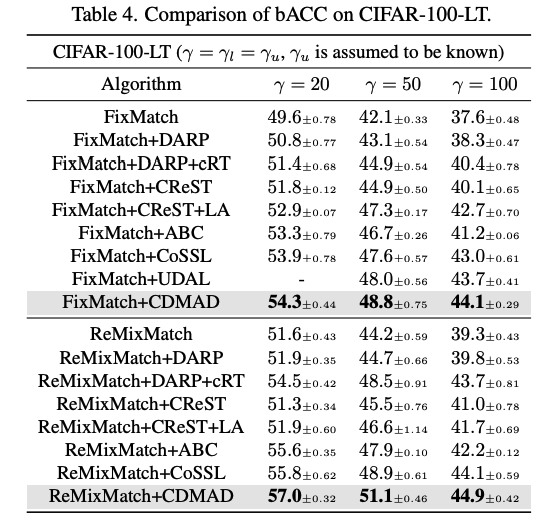
Table 4는 CIFAR-100-LT에 대한 실험 결과이다. 이를 통해 CDMAD가 많은 class를 가지고 있는 dataset에서도 잘 작동함을 확인할 수 있고, minority class가 매우 적은 양의 제한된 sample 수를 가진 상황에서도 기존의 기술들보다 좋은 성능을 보이고 있음을 확인할 수 있다.
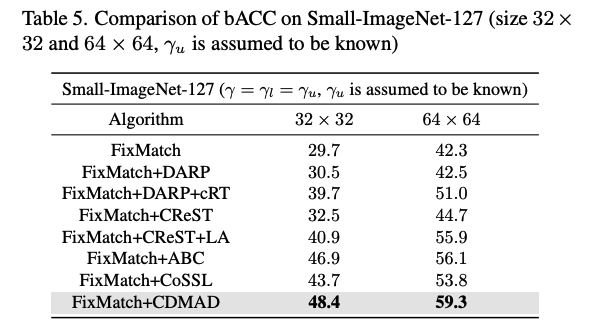
Table 5는 Small-ImageNet-127에 대한 실험 결과이다. CDMAD는 기존의 기술을 매우 큰 차이로 outperform 하고 있다. 다른 데이터셋들과 달리 Small-ImageNet-127 데이터의 test set은 class imbalance 한데, 이런 경우에서도 CDMAD가 효과적임을 알 수 있다.
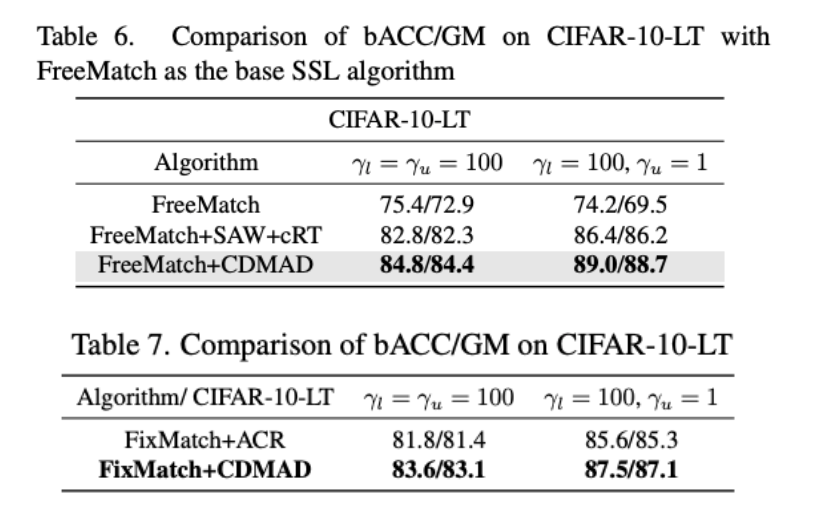
또한 비교적 최근 기술인 FreeMatch와 결합한 경우에도 높은 향상된 성능을 보이고 있으며, 최신 CISSL 기술인 ACR과 비교했을 때에도 훨씬 더 좋은 성능을 보인다.
Qualitative Results
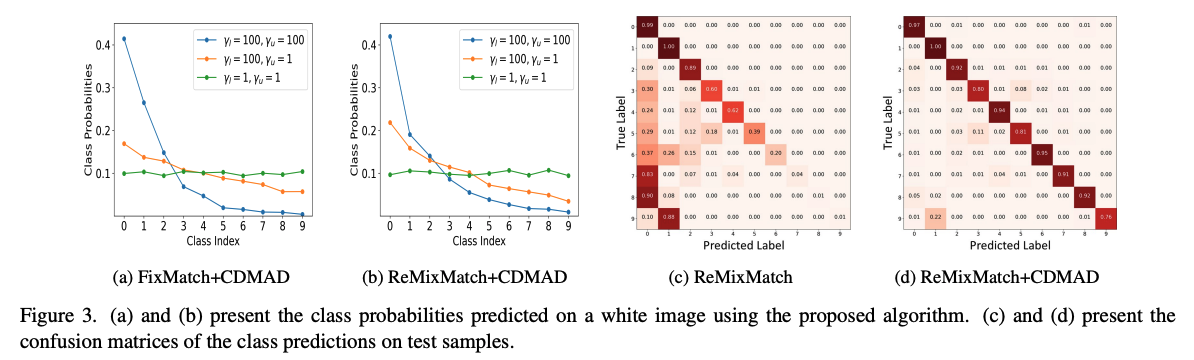
Figure 3의 (a)와 (b)의 주황색 그래프를 보면, CDMAD를 적용하기 전의 Figure 1에 나와 있는 그래프에 비해서 imbalance가 많이 완화되었음을 확인할 수 있다. (파란 그래프에 대해서는 논문에서 따로 언급하고 있지는 않았는데, 아마 labeled set과 unlabeled set에서 동일한 비율로 불균등이 심하게 있는 경우는 여전히 pseudo-label을 정제하더라도 절대적인 sample 량이 부족하기 때문에 long-tail 문제가 잘 해결되지 않은 것으로 보인다.)
Figure 3의 (c)와 (b)는

t-SNE를 통해 representation을 확인하더라도 CDMAD를 적용한 경우 cluster가 훨씬 더 깔끔하게 분리된 모습을 확인할 수 있다.
Ablation Study

Ablation study에서 CDMAD의 각 요소들이 어떤 효과성을 지니는지 보이고 있다. 개인적으로는 FixMatch에서 사용하는 confidence threshold를 사용했을 때 성능 저하가 발생한다는 점이 매우 흥미로운 것 같다. Confidence threshold는 낮은 quality의 pseudo-label을 학습에서 배제하기 위해 사용되는 hyperparameter인데, 이를 사용하지 않는 것이 더 좋은 성능을 보인다는 것은 pseudo-label의 정제가 어느정도 좋은 quality의 pseudo-label을 만들어내고 있다는 것을 보여주고 있다고 느껴진다. 논문에서 이러한 부분이 조금 더 강조되었다면 더 좋았을 것 같다. 또한 hyperparameter를 하나 제거함으로써 degree of freedom을 줄였다는 것도 매우 큰 장점인 것 같다.
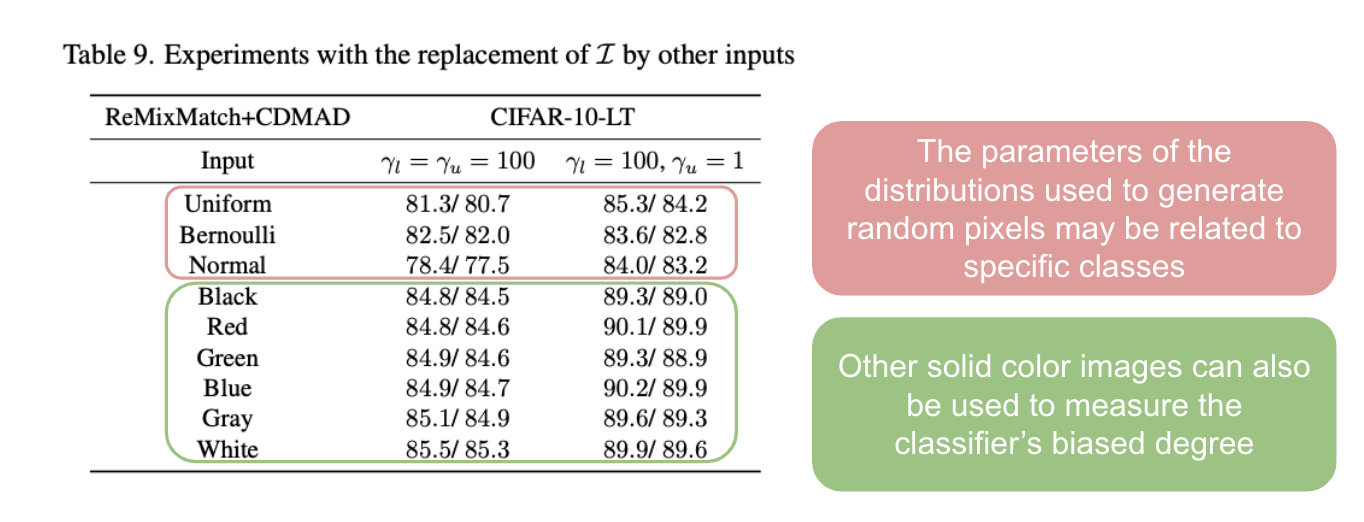

하지만 분류하고자 하는 이미지들이 color와 연관이 있는 경우, solid color image가 class label에 대해 non-informative하다는 assumption이 깨질 수 있다. 이러한 문제를 해소하기 위해, 저자들은 pixel 값이 [0, 255] 의 범위를 넘어서는 이미지 (사실상 non-image input) 을
Table 10에서 알 수 있듯이, non-image를 활용한 CDMAD도 white image와 매우 비슷한 정도로 성능을 보이고 있다. 이러한 결과는 non-image input도 classifier의 biased degree를 측정하는데 사용될 수 있음을 보여주며, 저자들은 이를 통해 class label에 대해 non-informative한 데이터를 찾아야 하는 어려움을 극복할 수 있다고 이야기 한다.
Conclusion
- 각 class에 편향된 정도 (biased degree)를 고려하여 SSL에서의 데이터 불균등 문제를 적절히 완화할 수 있는 CDMAD 알고리즘을 제안함. 이 메소드는 labeled 와 unlabeled set 사이의 distribution mismatch가 심하게 있더라도 효과적으로 문제를 완화할 수 있음.
- 4가지 벤치마크 데이터셋에 대해 진행한 실험은 CDMAD가 기존의 CISSL 알고리즘을 능가하고 있음을 보여주고 있음.
- Qualtative analysis와 ablation study는 CDMAD의 각 요소들의 효과성을 입증함.
간단하면서도 효과적이고, 코드 몇 줄만 추가하면 쉽게 기존의 메소드들에 적용될 수 있다는 점이 굉장한 장점인 것 같다. 또한 직관적으로도 이해하기 쉬운 메소드인 것 같다.
실험들 중에서는 특히나 LA에 대해 분석한 파트가 인상적이었다. 보다 구체적인 실험과 분석은 Appendix K에 나와있었는데, main paper에서 보고했어도 좋았을만한 실험과 분석인 것 같다. 기존의 여러 메소드들이 class distribution을 모르기 때문에 이를 예측하여 logit을 수정하는 등의 방식을 취했는데, CDMAD는 unlabeled distribution가 known이라고 가정하고 logit adjustment를 적용한 것보다도 훨씬 더 좋은 성능을 보이고 있다는 점에서 놀라움을 제공한다. 물론 unlabeled data의 distribution을 보다 정교히 활용할 수 있는 기법을 적용한다면 더 좋은 성능을 내는 알고리즘을 고안할 수 있겠지만, 단순히 unlabeled data에 대한 추가적인 분포 정보를 활용한 것보다 높은 성능을 낸다는 것만으로도 메소드의 효과성을 잘 보여주는 것 같다.
또한 나는 이 논문을 읽으면서 반드시 white image를 사용해야 하는가? 그렇다면 MNIST와 같이 white라는 color가 중요한 feature가 될 수 있는 dataset에서는 적용할 수 없는 것이 아닌가? 하는 생각을 가졌는데 다른 color 이미지와 random하게 생성한 이미지를 활용하여 ablation study를 진행하여 궁금함을 잘 해결할 수 있었다. 게다가 저자들은 이보다 더 나아가 우리가 image를 표현할 때 사용하는 수의 범위가 [0, 255]로 한정되어 있다는 점을 활용하여 non-image data를 만들고 이에 대한 실험을 진행한 것도 매우 흥미로웠다. 나였다면 이런 데이터를 사용해서 실험하는 것까지는 생각하지 못했을 것 같은데, 꽤 설득력 있는 실험이었다.
아쉬운 점은 qualitative result에서 CISSL SOTA 메소드와 비교하는 것이 없었다는 점이다. 사실상 단순 SSL 기법인 FixMatch와 ReMixMatch은 class imbalance 세팅에 매우 취약했을 것으로 예상된다. 이보다는 기존의 CISSL과 비교한 질적 평가가 더욱 의미있지 않았을까 생각한다.